
Personas That Matter – Elevating Chatbots Through Data-Driven Authenticity
How Can We Evaluate Our Chatbot Before Deploying It?
Imagine you’re about to launch a new chatbot. Everyone is excited, but the variety of real users it needs to handle is enormous. A few internal tests may not be enough to cover all possible scenarios that your chatbot will face in the real world.
Fortunately, it’s now relatively easy to generate a few hundred curated examples of potential user queries—often referred to as synthetic data. But here’s the challenge: How do we ensure that this synthetic data realistically captures the diversity of user personalities and the types of queries your chatbot will encounter once it goes live?
In this post, I’ll walk you through best practices for generating synthetic data. The workflow below provides a high-level overview of a process you can apply to create high-quality, authentic queries that will help you thoroughly test your chatbot before rolling it out.
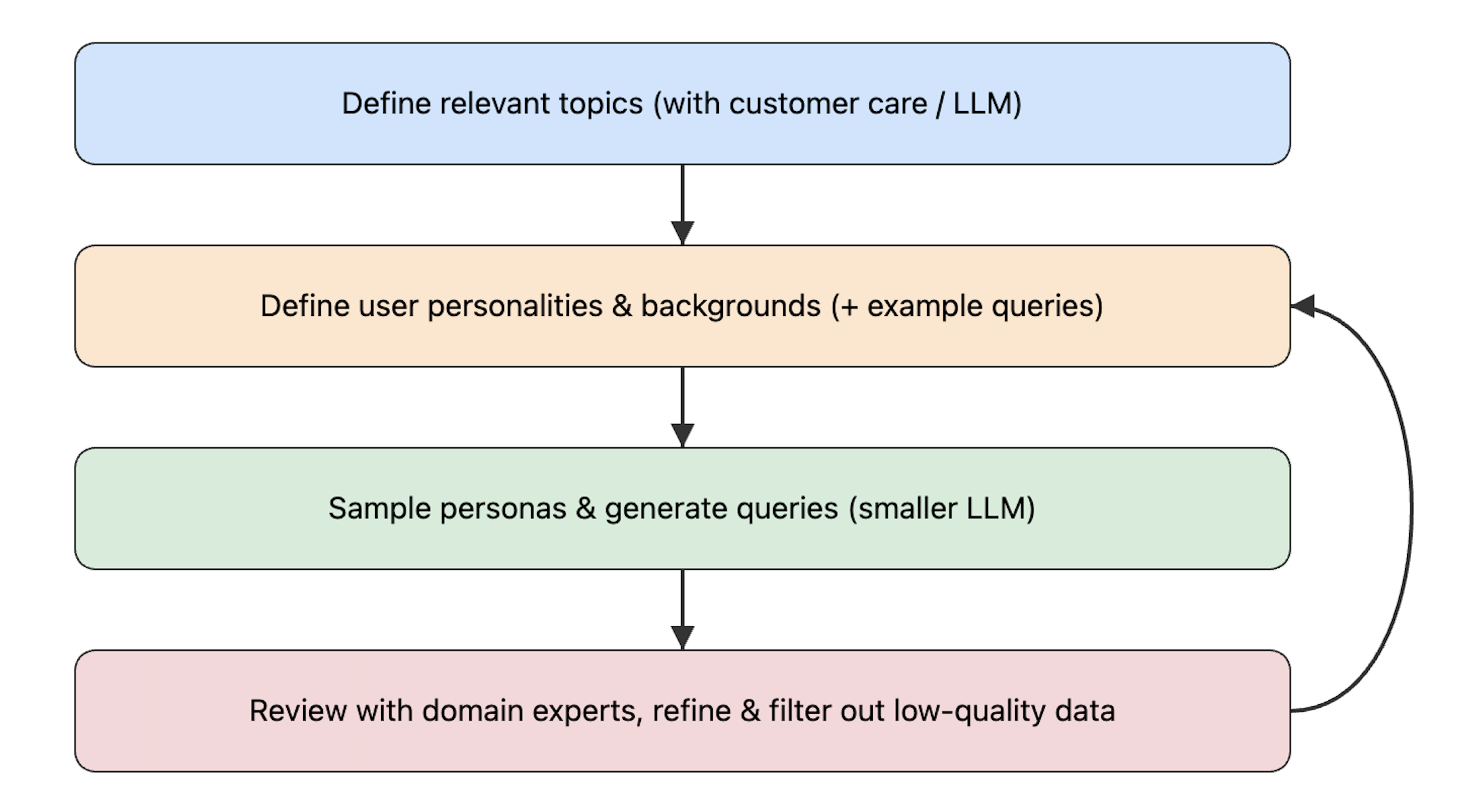
Below is a workflow diagram illustrating the process of creating and refining synthetic data for chatbot testing:
-
Define Relevant Topics: Collaborate with the customer care team or use an LLM to identify key areas where your chatbot must excel.
-
Define User Personalities & Backgrounds: Enrich each topic with realistic user profiles, complete with backstories and example queries.
-
Sample Personas & Generate Queries: Use a smaller LLM to produce synthetic questions based on the defined personas—capturing diverse tones and user needs.
-
Review & Refine: Domain experts validate the quality of these generated queries, discarding weak entries and fine-tuning prompts. If necessary, the process loops back to earlier steps to continuously improve coverage and authenticity.
Determine Relevant Topics and User Profiles
For this blog post, I used OpenAI’s o1 model to propose a fictional company and a product that we want to build a chatbot for. The next step was identifying relevant tools, topics, and user personas—then compiling them into a YAML file. This YAML file pairs each topic with potential user profiles and example queries.
The company profile I created is defined in a Markdown document, which we pass to the LLM as context when generating our synthetic data. In a real-world scenario, you or your client would craft a similar profile for an actual business use case. Below is an excerpt from the fake Millennia Bank profile which I used:
# Millennia Bank Information
Millennia Bank, established in 2002 in Berlin, is a consumer finance institution serving customers across Europe. The bank offers various products such as checking and savings accounts, loans, and multiple credit card lines. One of its primary offerings is the **MillenniaCard**, which comes in three tiers: **Classic**, **Platinum**, and **Student**.
...
An example of the topic/user profile pairs in the YAML file looks like this:
- topic: "Payment Not Going Through"
example_types:
- example_type: "Frantic Freelancer"
example_background: "Alex is a freelance graphic designer who depends on quick transactions and hates delays."
example_query: "I tried paying for a client’s stock images twice, and my MillenniaCard was declined both times! It’s embarrassing and I’m on a tight deadline—why is this happening?"
- example_type: "Nervous First-Timer"
example_background: "Daniel is new to credit cards and worries every time a payment doesn’t go through."
example_query: "I just tried to pay my phone bill online, but it was rejected. I’m not sure if I messed up the card details. Could you check if something’s wrong on my account?"
Although I used the o1 model to generate this YAML, in practice, you would likely collaborate with your client (or internal teams) to identify the most common and impactful topics. The idea is to make your synthetic data truly representative of real-world use cases—especially those edge scenarios that often slip through standard testing.
Naive approach
Before applying user profiles, let’s examine a basic approach to synthetic data generation. Essentially, we’d just provide the LLM with the company context, and nothing else. This inevitably leads to generic or one-size-fits-all queries. Below is a code snippet demonstrating this idea:
class SyntheticQuestion(BaseModel):
chain_of_thought: str
query: str
resp = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{
"role": "user",
"content": """Write a potential user query to a chatbot for the following product:
{{ data }}""",
},
],
response_model=SyntheticQuestion,
context={"data": client_description},
)
print(resp.chain_of_thought)
print(resp.query)
# > The user is likely interested in understanding the features, benefits, or specifics of the MillenniaCard. They could be considering which tier of the MillenniaCard is best suited for their needs, or they may have questions about fees, interest rates, or rewards. A suitable query would reflect an inquiry about the different card options and their associated benefits to help in making a decision.
# > What are the differences between the Classic, Platinum, and Student tiers of the MillenniaCard, and what benefits does each one offer?
Here, we’re using the instructor library for structured output, alongside OpenAI’s 4o-mini model. While the LLM generates a query that could be asked by a real user, it’s quite generic—missing any nuanced tone or situational detail. Up next, we’ll see how injecting user profiles (e.g., “Frantic Freelancer,” “Nervous First-Timer”) transforms these synthetic queries into more authentic reflections of real-world interactions.
Using Topics and User Profiles for More Realistic Queries
A more authentic result emerges when we incorporate topics and user profiles. Here’s the workflow:
-
Sample a topic (e.g., “Payment Not Going Through”) and an accompanying user profile (e.g., “Nervous First-Timer”) from our YAML file.
-
Provide the topic, user profile details, and the company context to the LLM.
-
Generate a fresh user profile corresponding to the given topic and a query that corresponds to that pair.
class SyntheticQuestion(BaseModel):
user_type: str
user_background: str
query: str
class Response(BaseModel):
topic: str
synthetic_question: SyntheticQuestion
synthetic_question = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{
"role": "user",
"content": """We want to generate synthetic data to evaluate the capabilities of the chatbot of our client.
Client description:
{{ client_description }}
To generate high quality data you will first come up with a user type and craft a small background about the user.
You will then craft a query for that user. You will be given a topic that the query will be about.
You will also be given an example for a user type, background and question for better understanding:
Topic: {{ topic }}
Example type: {{ example_type }}
Example background: {{ example_background }}
Example query: {{ example_query }}
Please make sure that the question is on the topic. It is highly important the generate user type, background and query are about the topic.""",
},
],
response_model=SyntheticQuestion,
context={"client_description": client_description, "topic": profile["topic"],
"example_type": profile["example_type"], "example_background": profile["example_background"],
"example_query": profile["example_query"]},
)
resp = Response(
topic=profile["topic"],
synthetic_question=synthetic_question
)
print(resp.topic)
print(profile["example_type"])
print(profile["example_background"])
print(profile["example_query"])
print(resp.synthetic_question.user_type)
print(resp.synthetic_question.user_background)
print(resp.synthetic_question.query)
# > Requesting an Additional Card
# > Roommate Sharing Bills
# > Iris splits rent and groceries with her roommate, hoping to consolidate spending on one card.
# > Could I get a second card for my roommate? We share expenses, and it’d be simpler to manage everything on one statement.
# > Student Cardholder
# > Mark is a university student who has just received his first MillenniaCard Student. He is eager to manage his finances better and enjoys using mobile apps for tracking expenses, especially since he has limited income from part-time work.
# > Can I get an additional card for my parents to help them manage shared expenses? It would make it easier for us to handle costs when they support me in my studies.
Why This Matters
Compare the naive approach:
“What are the differences between the Classic, Platinum, and Student tiers of the MillenniaCard, and what benefits does each one offer?”
with the improved one:
“Can I get an additional card for my parents to help them manage shared expenses? It would make it easier for us to handle costs when they support me in my studies.”
The second query feels far more realistic, capturing a specific user type and scenario. This technique—mixing persona data with context—helps test your chatbot’s ability to handle real-world nuances rather than just generic FAQs.
What’s Left?
So far, we’ve demonstrated how to generate a single data entry—which obviously won’t cover all real-world scenarios. In practice, you’d likely:
- Generate a Larger Dataset
Leverage asynchronous calls to the OpenAI API to quickly produce hundreds of synthetic queries.
- Review with Domain Experts
Have specialists check whether each query truly reflects real-world user concerns.
- Iterate & Refine
Adjust prompts, user profiles, or system settings as needed—especially if you spot edge cases or off-target questions.
Once you’ve collected around 200 samples, you can feed them into your chatbot, observe the responses, and evaluate alignment with expected outcomes. Where mismatches appear—whether in tone, accuracy, or content—you can fine-tune the system prompts or the LLM’s overall configuration.
All the code shown here is available on my GitHub. Feel free to explore, experiment, or reach out if these techniques might benefit your own chatbot projects!